
¿Tus datos y equipos van sin rumbo?
La brújula que te guía y conecta al éxito
Transformamos el caos en claridad con datos accesibles y visuales, para decidir sin depender de técnicos.
Solicita tu diagnóstico gratuito¿Por qué confíar en nosotros?
Decisiones basadas en datos
Evita perderte en métricas confusas. Visualizamos lo que importa para decidir mejor.
Descubre cómo →Equipos conectados
Alineamos marketing, talento y negocio para que trabajen juntos, sin silos ni barreras.
Perspectiva humana
Conectamos datos con personas, impulsando motivación y colaboración.
Transformamos datos en resultados
Caso de Estudio: Prevención del Churn de Clientes con Machine Learning
El Desafío
El churn o pérdida de clientes representa uno de los mayores retos financieros para las empresas, especialmente en sectores altamente competitivos. El costo de reemplazar un cliente perdido supera con creces el costo de retención. Nuestro objetivo fue doble: predecir qué clientes tienen mayor probabilidad de churn y estimar el beneficio económico de intervenir con acciones personalizadas para retenerlos.
Construcción del Dataset
Para esta solución, analizamos cinco datasets representativos de diferentes industrias: ecommerce, telecomunicaciones, banca, servicios en streaming y entornos B2B. Cada dataset fue tratado individualmente, aplicando limpieza, codificación de variables categóricas y normalización.
El desbalance en la variable target (churn vs no churn) se abordó con técnicas de estratificación y evaluación centrada en métricas como el F2-score y el recall, priorizando la detección de clientes en riesgo.
Modelado Predictivo y Optimización
Probamos distintos algoritmos incluyendo Decision Trees, Random Forests, Logistic Regression y CatBoost. Cada modelo fue optimizado con Optuna, ajustando hiperparámetros como profundidad, regularización y número de iteraciones.
Para maximizar el impacto económico, se seleccionó el mejor threshold en función del F2-score, manteniendo una precisión mínima aceptable. Se priorizó el recall, ya que identificar correctamente a los clientes que se irán tiene mayor impacto financiero que intervenir a un cliente que se habría quedado.
Análisis de SHAP Values
Los valores SHAP nos permitieron entender qué factores explican el churn en cada cliente. Estos insights fueron clave para diseñar estrategias de retención personalizadas, considerando las variables más influyentes: tiempo como cliente, número de llamadas a soporte, tipo de contrato, actividad reciente, etc.
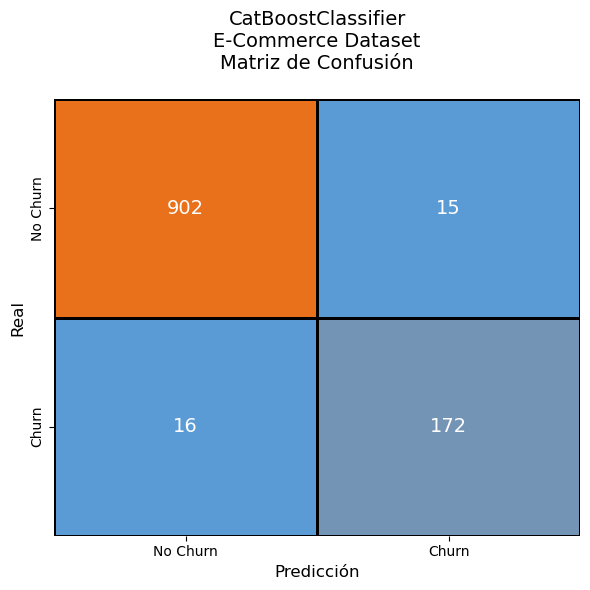
Matriz de Confusión: Ejemplo de desempeño del modelo en un dataset de ecommerce, con alta precisión y bajo número de falsos negativos.
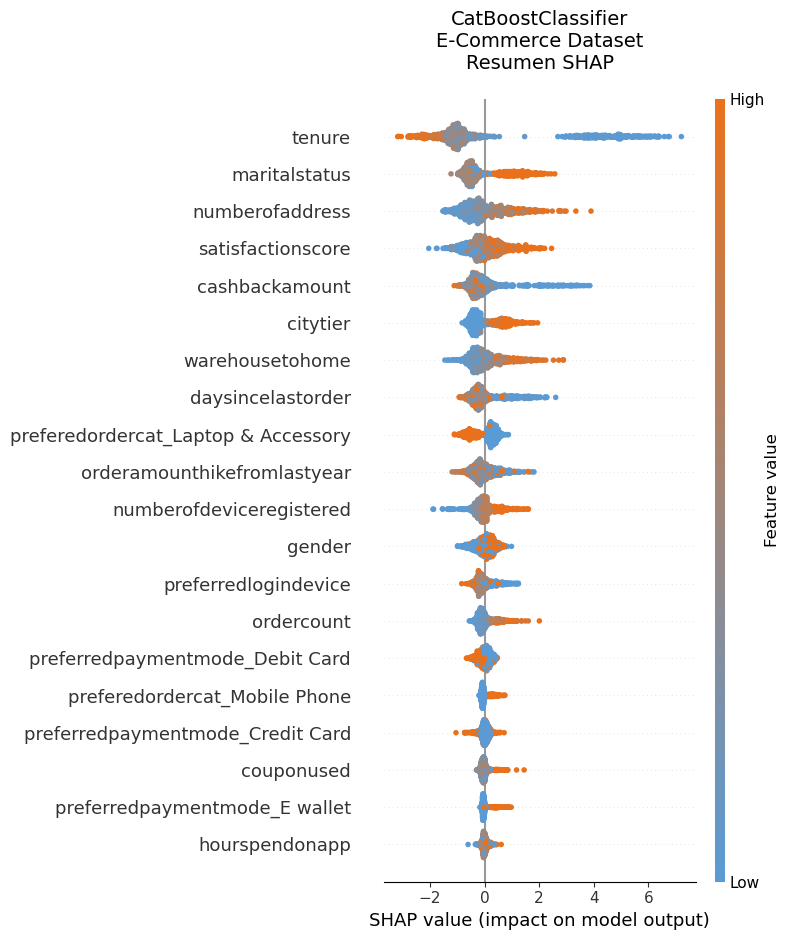
Resumen SHAP: Importancia global de cada variable en el modelo de churn para ecommerce, destacando factores como la antigüedad del cliente, estado civil y nivel de satisfacción.
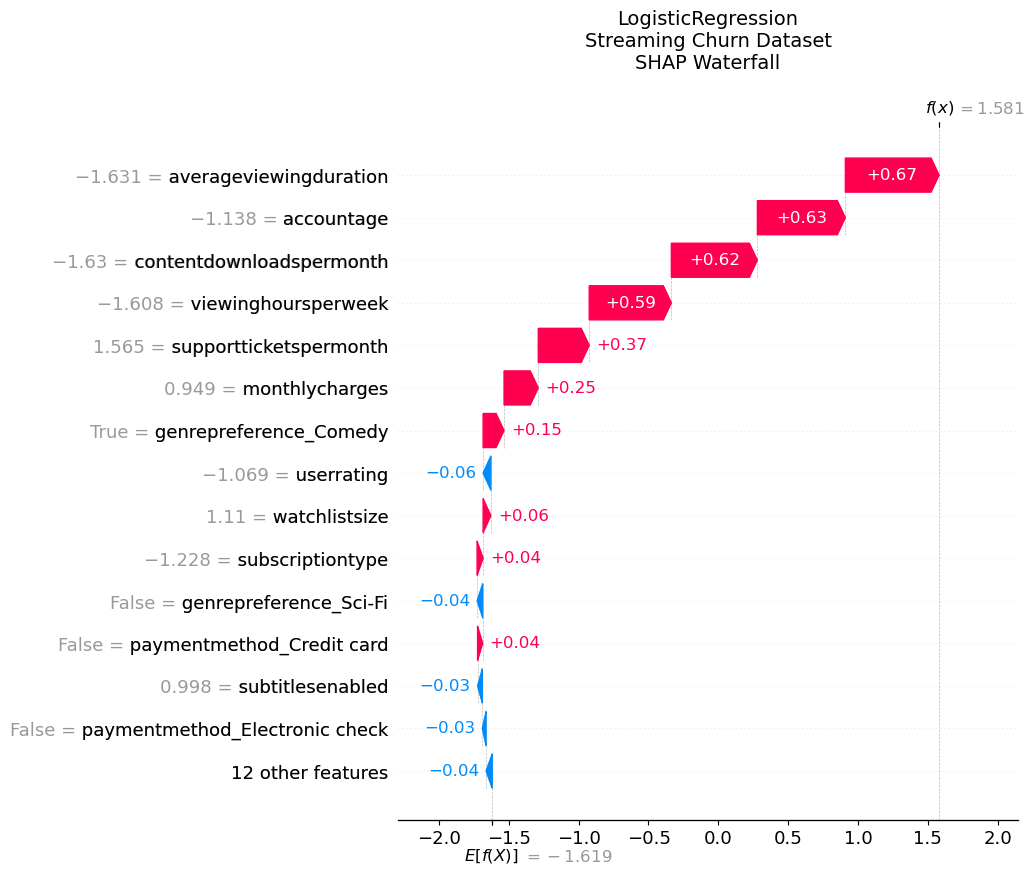
Waterfall SHAP: Visualización individual para explicar el riesgo de churn de un cliente específico.
Impacto Económico: Simulación de Ahorros
Se estimó el costo de no hacer nada (churn sin intervención) y se comparó con el costo de intervenir con una campaña de retención, considerando la tasa de éxito esperada y el gasto por cliente. Los resultados fueron:
E-Commerce Dataset
Ahorro: €32,605
Clientes Salvados: 112
Intervenciones: 187
ABT Churn Dataset
Ahorro: €39,960
Clientes Salvados: 67
Intervenciones: 228
Telco Customer Churn
Ahorro: €50,470
Clientes Salvados: 140
Intervenciones: 558
Streaming Churn
Ahorro: €125,055
Clientes Salvados: 1121
Intervenciones: 3143
Bank Customer Churn
Ahorro: €45,700
Clientes Salvados: 58
Intervenciones: 310
Estrategias de Intervención Basadas en Interpretabilidad
En lugar de aplicar campañas genéricas, propusimos acciones personalizadas basadas en los factores SHAP individuales que causan riesgo de churn. Por ejemplo:
- Clientes con bajo número de interacciones: enviar campañas de reactivación con contenido relevante.
- Usuarios con caídas recientes en la actividad: ofrecer descuentos puntuales o soporte personalizado.
- Clientes con bajo score de servicio: contacto directo desde atención al cliente para resolver incidencias.
Estas acciones, de bajo coste y alto impacto, pueden mejorar la tasa de éxito y justificar aún más la inversión en modelos predictivos.
Estrategia: Selección de Modelo y Segmentación
Una conclusión clara de este estudio es que no existe un único modelo que funcione bien en todos los sectores. Mientras que en ecommerce o streaming los modelos actuales ofrecen un ahorro neto sustancial, en entornos como banca o telecomunicaciones el coste de intervenir a clientes que no se iban (falsos positivos) puede superar el beneficio.
Por ello, planteamos la integración futura de un selector automático de modelos que combine:
- La predicción del modelo más adecuado según el sector y los datos disponibles.
- Una evaluación económica previa (coste vs beneficio) antes de activar cualquier intervención.
Este enfoque permitirá aplicar estrategias diferenciadas por tipo de cliente, activando el modelo solo cuando haya un retorno de inversión positivo.
Segmentación: Intervenir Solo Donde Tiene Sentido
Los sectores con menor margen —como telecom o banca— pueden beneficiarse de una segmentación inteligente de la intervención. En lugar de actuar sobre todos los clientes con alta probabilidad de churn, proponemos limitar las campañas a:
- Clientes en el top 50 % de riesgo de churn (según probabilidad del modelo).
- Clientes con alto valor estimado (por ejemplo, ingresos o antigüedad).
En el caso del dataset ABT Churn (B2B), aunque el coste de intervención es bajo, los errores pueden tener mayor impacto si se pierde un cliente valioso. Una intervención más precisa, combinando los scores del modelo con información adicional del account manager, podría reducir falsos positivos sin sacrificar recall.
Para Telco, la intervención masiva genera costes difíciles de amortizar. Aquí recomendamos revisar el threshold, mejorar la precisión del modelo o añadir reglas de negocio que prioricen la intervención solo donde tiene sentido.
El caso de Bank Churn sirve como ejemplo de lo que no debe implementarse sin evaluación económica. A pesar de métricas aceptables, el modelo falla más de lo que acierta. Es un recordatorio de que incluso modelos bien calibrados necesitan validación económica antes de su despliegue.
Conclusión y Próximos Pasos
El uso de modelos de machine learning para la predicción del churn ofrece un enorme potencial, pero debe ir acompañado de evaluación económica, segmentación y explicabilidad. Nuestra solución demuestra que es posible estimar el ahorro esperado, justificar las intervenciones y adaptar la estrategia a cada sector.
En siguientes fases, proponemos:
- Integrar nuevos datasets y sectores.
- Desarrollar un sistema de recomendación de acciones basado en SHAP.
- Construir un dashboard interactivo para la activación y seguimiento de campañas de retención.
Hablemos de tus datos
Cuéntame tu situación y en menos de 48 h te responderé con una propuesta personalizada, sin compromiso.
Nos tomamos muy en serio tu privacidad. Solo usaremos tus datos para responder a tu consulta.